Icicle and Flame Maps
Job van der Zwan
Introduction
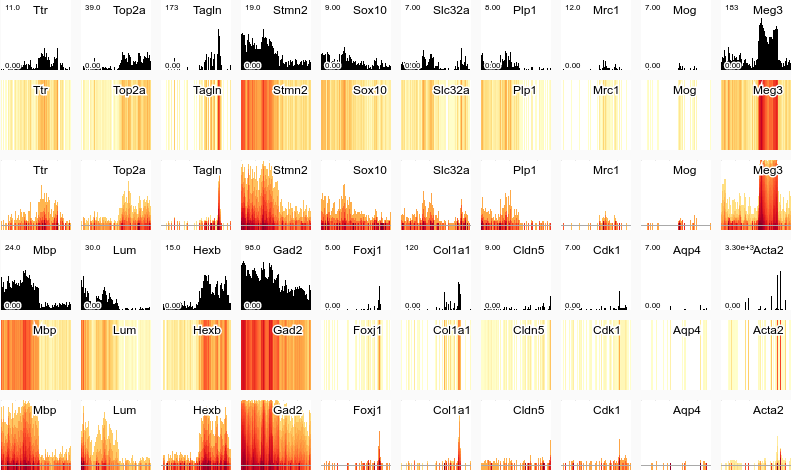
Icicle and flame maps (not to be confused with icicle plots or flame graphs) are a novel type of plot (as far as we can tell), originally designed at Linnarsson Lab to cope with issues that arose due to having far more raw data to show than available screen resolution. Specifically, they avoid issues of smoothing out information through averaging. In a flame map, the "height" of a column shows the ratio of zero to non-zero values in that column. The heat map gradient of the column shows the actual values. Below a few example small multiples of bar graphs, heat maps, and flame/icicle maps are displayed, using the same data.
(The data is taken from "Cell types in the mouse cortex and hippocampus revealed by single-cell RNA-seq", A Zeisel, AB Muñoz-Manchado, et al. 2015. However, the data itself does not really matter for what we are trying to demonstrate)
Note that icicle maps are just upside-down flame maps with a different color scale. As they are identical otherwise, we will use flame maps as the standard example from now on.
Original Scientific Context
Flame and icicle maps were designed to solve a specific problem, and knowing the problem they originally tried to solve may make it easier to understand them.
Linnarsson Lab does research in the field of molecular neurobiology, using Single cell RNA sequencing (scRNAseq). The lies-to-children explanation of what we do is as follows:
- Take a sample of cells (the biological kind)
- Measure gene expressions for each cell: "is gene Mog active, is gene Plp1 active, etc.". This is measured by counting RNA molecules for that gene (for those unfamiliar with this field of biology, "RNA molecules" can be thought of as "active copies of that gene" here)/li>
- Try to identify which genes are associated with which cell type
- Combine this with sampling from different developmental stages to untangle the genetic side of cell development
The idea is to identify cell types by their active genes (for example, discovering new types of neurons). Since we don't know a priori what the relevant genes will be, the number of genes measured is essentially "as much as one can get away with" (typically tens of thousands). Similarly, for purposes of statistical strength, the cell sample size is "as big as one can get away with", which is rapidly increasing in this field: data sets of tens of thousands of cells are common now, hundreds of thousands are starting to pop up and surely a million is not far off.
The end result is a data set that is basically a giant table, with columns representing individual cells, rows representing genes, and cells in the table representing how much RNA was measured of that gene in that particular (biological) cell. Most of these cells will be zero, because the gene is not active - we have a sparse data set.
To make sense of the data, clustering algorithms are used to sort the rows and columns of this table, so that similar cells and genes end up close together. The next step is to inspect individual rows of this table for "marker genes" - genes whose activation (or lack thereof) can be used to categorise cell types. That is where these plots come in.
Unlike most charts, the x-axes of the plots used in this article do not represent a value like time, or clear-cut categories. It's just cells, ordered by "heuristic likeness" (to the best of our cluster algorithm's ability), grouped evenly across available columns of our plot.
When we use a bar graph to plot a gene row, each column in the graph simply takes a portion of our original row. Say we have 100.000 cells, but only 1000 pixels to display them. Even if we make the columns of our bar graph as narrow as a single pixel, they still represent 100 cells, typically by averaging their values. The first column takes the first 100, the second column the next 100, and so on.
Issues introduced by grouping and averaging
Three interactive plots should be displayed below: one bar graph, one heat map, and one flame map. The plots show levels of gene expression in a selection of mouse cells for a given gene.
For heat maps and flame maps, missing values are displayed as grey, zero values are displayed as white, and non-zero values scale from yellow for low values, to red for high values.
The plots should be 800 pixels wide, and for demonstration purposes the width of the columns is at least four pixels. That means they can display at most 200 columns (assuming this is viewed on a display with a high enough resolution. We try to compensate for smaller screens, zoom settings, and high density displays, but it might not be completely right. Apologies, it is very hard to make dynamic plots behave the same across different media).
Try changing the number of plotted cells, while predicting how different amounts of data affect the shape plot itself:
{Introduction Interactive Demo}
Notice the change once the number of cells exceeds 200. How the graphs change when wiggling the value around 300 is also very revealing.
Large relative differences when averaging small group sizes
Any data set larger than the maximum amount of columns requires grouping the data, in this case any data set bigger than 200 cells. For the bar graph and heat map we typically group the data as evenly as possible, then plot the average value per group (that is, per column).
Compare plotting 298, 299, and 300 cells. In this range the columns alternate between grouping one and two data points. A tiny bit of wiggling has a big effect on how the data is distributed. To make matters worse, for bar graphs and heat maps there is no direct visual way of telling how this is done, hiding it from the reader. Admittedly, the data-to-group ratio in this example is specifically chosen to maximise that effect, but it illustrates the point.
Averaging away information
Often, averaging is a good thing, smoothing away noise and outliers. In our case it can hide useful information. It may be important to know in how many cells a gene is expressed. In other words: the sparsity of the data. This is a separate thing from the actual value of expression. Averaging reduces these two types of information to one number.
The bar graphs also tend to decrease in height when there is more data per column, and the heat maps tend to fade (try Hexb, without log scaling, and slowly increase values while while observing the left side of the plot). Because our data is sparse, averaging tends to skew values towards zero. When we have very large data sets, this can even mask non-zero values, although log-scaling the vertical axis helps a bit here.
(Aside from using a log-scale, there are more sophisticated alternatives to averaging that can help as well, like Steinarsson's Largest Triangle Three Buckets algorithm, but they have their own trade-offs)
How flame maps attempt to address these issues
The aforementioned problems are simplified examples of the problems highlighted by Anscombe's Quartet, or the more recent 'Datasaurus Dozen' by Matejka and Fitzmaurice. Like the graphs in these papers, the most straight-forward solution would be representing the raw data being grouped.
Construction
Similar to how we use bar graphs and heat maps, flame maps group the input data in order, and as evenly as possible across the available columns. However, instead of averaging these values, each column sorts their values, and plots them a vertical heat map (if we have only one data point per column, the result is effectively a regular heat map). The typical look of the plotted gradients gives the flame map its name.
So in our original scRNAseq context, cells (samples) are ordered along the x-axis according to clustering algorithm. Each column represents groups of either n or n-1 cells, where n is total cells divided by total columns, rounded up. The y-axis counts the occurrences of cells with an gene expression given by the colour.
Construction example
Let's walk through an example construction step by step. We will take {this.introSetAmountLink(100, 'the first hundred values')} of Meg3 as our example data, which has the following values:
[
0, 4, 4, 0, 4, 4, 1, 2, 0, 0,
0, 0, 0, 0, 1, 0, 5, 10, 0, 0,
1, 1, 0, 1, 0, 0, 0, 0, 0, 1,
0, 0, 0, 0, 0, 0, 0, 0, 3, 0,
0, 0, 0, 0, 0, 0, 0, 3, 2, 0,
1, 1, 0, 2, 3, 1, 0, 2, 2, 0,
6, 4, 2, 8, 8, 2, 0, 5, 1, 4,
3, 4, 3, 0, 4, 5, 3, 0, 3, 0,
1, 0, 0, 3, 0, 2, 5, 1, 0, 3,
1, 3, 0, 0, 0, 0, 4, 2, 3, 1,
/* rest of the data */
]
Lets say that our plot settings works out to grouping ten data points per column:
(in our opening plot this would be {this.introSetAmountLink(2000, 'showing the first 2000 elements')})
[
[0, 4, 4, 0, 4, 4, 1, 2, 0, 0],
[0, 0, 0, 0, 1, 0, 5, 10, 0, 0],
[1, 1, 0, 1, 0, 0, 0, 0, 0, 1],
[0, 0, 0, 0, 0, 0, 0, 0, 3, 0],
[0, 0, 0, 0, 0, 0, 0, 3, 2, 0],
[1, 1, 0, 2, 3, 1, 0, 2, 2, 0],
[6, 4, 2, 8, 8, 2, 0, 5, 1, 4],
[3, 4, 3, 0, 4, 5, 3, 0, 3, 0],
[1, 0, 0, 3, 0, 2, 5, 1, 0, 3],
[1, 3, 0, 0, 0, 0, 4, 2, 3, 1],
/* rest of the data */
]
The values in the groups are then sorted:
[
[0, 0, 0, 0, 1, 2, 4, 4, 4, 4],
[0, 0, 0, 0, 0, 0, 0, 1, 5, 10],
[0, 0, 0, 0, 0, 0, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 3],
[0, 0, 0, 0, 0, 0, 0, 0, 2, 3],
[0, 0, 0, 1, 1, 1, 2, 2, 2, 3],
[0, 1, 2, 2, 4, 4, 5, 6, 8, 8],
[0, 0, 0, 3, 3, 3, 3, 4, 4, 5],
[0, 0, 0, 0, 1, 1, 2, 3, 3, 5],
[0, 0, 0, 0, 1, 1, 2, 3, 3, 4],
/* rest of the data */
]
And plotted top to bottom: (replacing zeros with dots here, for ease of reading)
. . . . . . . . . .
. . . . . . 1 . . .
. . . . . . 2 . . .
. . . . . 1 2 3 . .
1 . . . . 1 4 3 1 1
2 . . . . 1 4 3 1 1
4 . 1 . . 2 5 3 2 2
4 1 1 . . 2 6 4 3 3
4 5 1 . 2 2 8 4 3 3
4 10 1 3 3 3 8 5 5 4 ...
The actual resulting plot looks like this:
{Fig: Constructed Plot}
As mentioned, the same shape can be seen in the introduction plot above when {this.introSetAmountLink(2000, 'set to 2000 elements')}.
Using more space and colour dimensions
Heat maps (as used here) only use horizontal position and colour, and bar graphs use horizontal position and height (colours are usually limited to grouping clusters by category). Flame maps use width, height and colour to indicate different things, effectively having one extra "dimension" at their disposal to communicate information.
In a flame map, the "height" of a column shows the count of non-zero values in that column. The gradient of the column gives an impression of the actual values (height is fixed at the biggest column size, and for groups with less data a grey block signals the missing element).
For example, when plotting between 201 and 400 cells in the example above, we can immediately see when we are grouping two values or one, and what their separate values are. Meg3 is another good example of where this adds information: there is a chunk where nearly all cells are non-zero, but expression level varies. This could not be discerned on the heat map or bar graph.
Even when we have more data per column than vertical pixels, and are therefore forced to average data per pixel, this is less of a problem than before: because the data is sorted, the values being averaged are likely to be (nearly) the same value.
Dealing with very sparse data
Sometimes the data is so sparse that only the bottom tile of a flame map column contains non-zero values. If our columns are only two to four data points high (400, 600 and 800 cells in the above demo), these are still readable, but when the data-to-pixel ratio is bigger, we end up with our sparse-data averaging problem again.
For example, in the small multiple that opened the article, each cell has only one or two pixels. With sparse data, this makes non-zero values hard to spot.
To compensate for this, flame maps default to adding a thin strip below the main plot, that shows the maximum value of the column above it. These are separated by a grey line, to avoid confusing this with a higher number of expressed cells:
{Small Multiples Repeat}
For very sparse data, the extra strip makes the presence of non-zero values stand out.
Caveats of using flame maps
We do not want to suggest that flame maps are a drop-in replacement for bar graphs and heatmaps. They have their own trade-offs and potential issues.
Simpler alternatives
Even when showing sparsity and preventing deceptive averages is important, there might be simpler alternatives. When that is all that we want to know, we can also sort the data as a whole, instead of per column, which is an easier to interpret visual solution:
{Sorted Plot Examples}
However, when the order of data matters this is not an option. In our case, we want to compare clusters of cells, so regardless of which order we choose, it has to stay constant across plots.
Aliasing
Grouping data inherently makes it susceptible to aliasing issues. Below is an interactive that demonstrate this the effects. The data alternates between one and zero. Tweak the values of how quickly it alternates, with which offset, and with which plotsettings, to explore the aliasing issues that can arise:
{Aliasing Examples}
As can be seen, the data only really makes sense when we zoom in far enough that each cell is plotted separately. However, bar graphs and heat maps perform just as poorly.
The cause of the problem is not really the type of plot being used. If something like this would show up in a real data set, the problem is likely either the choice of algorithm that lead to said ordering, or the data itself.
The point however is that, unlike the issues caused by sparsity or averaging, flame maps are just as susceptible to this as bar graphs and heat maps.
Imprecision of colour comparisons
If we want to determine how much two values differ, human perception is less precise when comparing colours than when comparing sizes. Ignoring the aforementioned issues with averaging, flame maps and heat maps both have a disadvantage over bar graphs here.
With that in mind, for anything that requires more precise interpretations than comparing zero-values, low non-zero values, and high non-zero values, we advise against using flame maps (or heat maps). Providing more fine-grained controls like clipping, tresholding and log-scaling the data may also help.
Optical illusions
As of writing this is purely speculative, but it seems plausible that certain colour gradient arrangements can lead to optical illusions, like the simultaneous contrast effect, Mach bands, and the watercolour illusion. Similarly, optical illusions related to perceived sizes being affected by nearby sizes are well documented - i.e. the Ebbinghaus illusion.
We believe this is worth investigating, as these kinds of optical illusions would interfere with the correct interpretation of the underlying data. Of course, both heat maps and bar graphs may also have such problems, but since flame maps combine size and colour they might be more susceptible to them, or suffer from novel illusions that arise from the combination. It may also be interesting to see if flame maps and icicle maps perform differently in this regard.
Summary
When compared to traditional bar graphs and heat maps, due to not averaging grouped data, flame maps let us:
- discern whether grouped data contain many low values, or a few high values
- discern the ratio zero to non-zero values
- empasize the presence of non-zero values when data is extremely sparse
In situations where these are desired properties, and a very precise distinction between high and low values is not required, we think they will provide advantages.
They are, in our opinion, very simple to construct, to the point where we are still not sure if they are really novel or if we simply have not looked hard enough. If they do already exist under another name, and with implementations in major plotting packages, please let us know. It would make the people in our group very happy (see below).
Implementations
I'll switch to first person here, because this is a WIP. For now, this website is the only implementation. Sorry. The source code for it can be found at:
https://github.com/linnarsson-lab/flamemaps
Flame maps were created for a for-now in-house web app. For performance reasons they were implemented in raw javascript and html5 canvas (not even a framework like d3.js was used). This demo page is based on repurposed plotting code from this web app. I do not know PyPlot, R or any other plotting library really, and currently don't have the time it would take to learn them well enough to implement these plots efficiently. So I figured it made more sense to write a convincing demonstration page and hope that others will agree these plots are useful, in the hope that the various plotting library wizards out there take over from there. And then Gioele can stop wishing I'll learn how to use PyPlot to implement this for him - Job van der Zwan
Interactive Demos
Acknowledgements
The author would like to thank his colleagues at the Linnarsson Lab group for early feedback on these plots, and Sten Linnarsson in particular for being given the freedom to explore this side-project. We thank Xan Gregg for suggesting the Icicle Plot variant. Finally, we thank Stefan Hoj-Edwards at The Roslin Institute, University of Edinburgh, for discussions that helped tremendously with finding and correcting sloppy wording and confusing descriptions.